
“答”问如流 妙“辩”连珠 | 研究生答辩风采展示:信息管理系张力元、严承希
编者按:百年大计,教育为本。为全面提高人才培养质量,着力培养担当民族复兴大任的时代新人,北京大学深入贯彻落实习近平总书记关于教育的重要论述,坚持立德树人的根本使命,瞄准科技前沿和关键领域,以全员、全过程、全方位育人为基础,严格执行全过程管理,优化答辩程序及制度,坚持学位授予高标准,蹄疾步稳,教育改革取得扎实成效。学位论文答辩是研究生培养过程和培养成果的集中体现,是研究成果展示的重要平台。研究生院推出“‘答’问如流 妙‘辩’连珠——北京大学研究生答辩风采展示”系列报道,将各院系答辩特色做法和精彩瞬间汇集成文,集中展现研究生的科研能力和综合素养,为各院系进一步提升培养质量提供借鉴与参考。
孟夏时节,别院簟青。在北京大学方李琴楼420教室里,北京大学信息管理系2017级情报学专业博士研究生张力元和2016级情报学专业博士研究生严承希顺利通过了博士学位论文答辩。张力元与严承希是北京大学第一批数字人文方向的博士研究生,导师为北京大学数字人文研究中心主任,北京大学信息管理系王军教授。两位博士研究生的学位论文研究工作均依托于北京大学数字人文研究中心与哈佛大学费正清中心联合申请的“中国儒家学术史知识图谱构建研究”国家自然科学基金国际重点合作项目。
博士学位论文答辩主要由论文陈述、专家学者提问及答辩委员会投票表决三个环节组成。答辩委员会主席为北京大学图书馆副馆长、北京大学智能科学系童云海教授。成员有浙江大学人文学院徐永明教授、北京大学信息管理系王继民教授、清华大学经济管理学院刘红岩教授、北京大学王选计算机研究所万小军教授。童云海教授长期从事数据仓库研究,目前负责图书馆数据资源建设及服务。徐永明教授是国内数字人文先驱者,负责“学术地图发布平台”项目,主持“明代文学智慧大数据及平台建设”国家社科基金重大项目。王继民教授在机器学习、Web数据挖掘、科学评价、信息可视化等方向有突出成就。刘红岩教授在大数据管理与分析、数据与文本挖掘、商务智能等方向的国际顶尖及高水平期刊上有诸多研究成果发表,获得11项国家发明专利授权,获得国际会议最佳论文奖6次。万小军教授在自然语言处理与文本挖掘方向是领军人物,荣获ACL2017杰出论文奖、IJCAI 2018杰出论文奖、2017年吴文俊人工智能技术发明奖等奖励。此次答辩委员会汇集了国内智能科学、大数据、文学史、古籍整理、信息管理等领域的重量级学者,充分展现了数字人文跨学科交流的特点,也肯定了北京大学在数字人文方向上的实力。
张力元的博士学位论文题目为《基于机器学习的古典目录学互著与别裁方法研究》。张力元指出,互著与别裁是古典目录学中两种辅助著录方法,但具有时代局限性,完全基于人工实现会存在效率、成本、客观性、可靠性等方面的问题。对此,她提出可以将互著与别裁映射为文本挖掘中的文本分类任务,并借助机器学习方法加以实现。
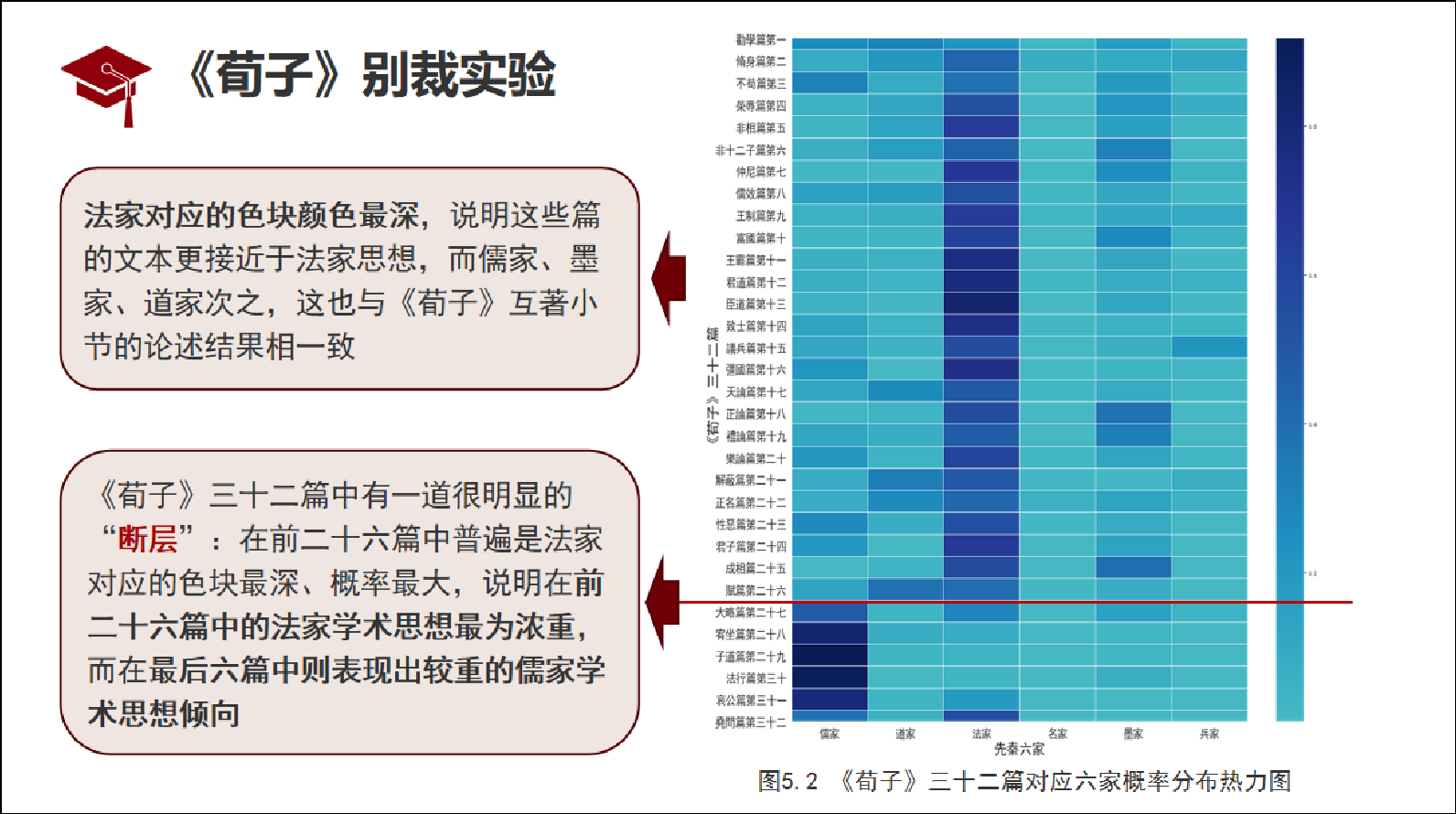
张力元答辩展示内容
张力元分别使用TextCNN模型和BERT模型,利用先秦诸子六家十部典籍文本进行典籍与学派的分类训练,发现BERT模型在先秦小规模古汉语语料上也可以取得90%以上的分类准确率,分类效果比TextCNN模型理想。她进一步利用在先秦文本上微调后的BERT模型对《荀子》与《管子》两部典籍分别进行全书、篇、章为粒度的分类实验。模型可以生成各粒度文本属于各学派的概率,可以判别《荀子》与《管子》思想倾向性,并得到互著与别裁结论。将模型得到的结论与传统人文研究结论相比较,共同之处可构成三角论证增强相关结论可信性,不同之处可以启发进一步的问题探讨。该研究可以在目录学领域内加强对古籍资源的组织与利用,也可以在学术史领域内拓宽对典籍及思想的分类辨别维度。


答辩现场
严承希的博士学位论文题目为《基于主动学习的古籍命名实体识别研究》。基于深度学习方法,严承希提出了一个面向汉语古籍的命名实体识别任务的三层框架。该框架不仅有效弥补了汉语古籍领域命名实体识别研究的不足,还可以推广至其他“少样本”领域命名实体识别模型的自动训练和构建方案中。
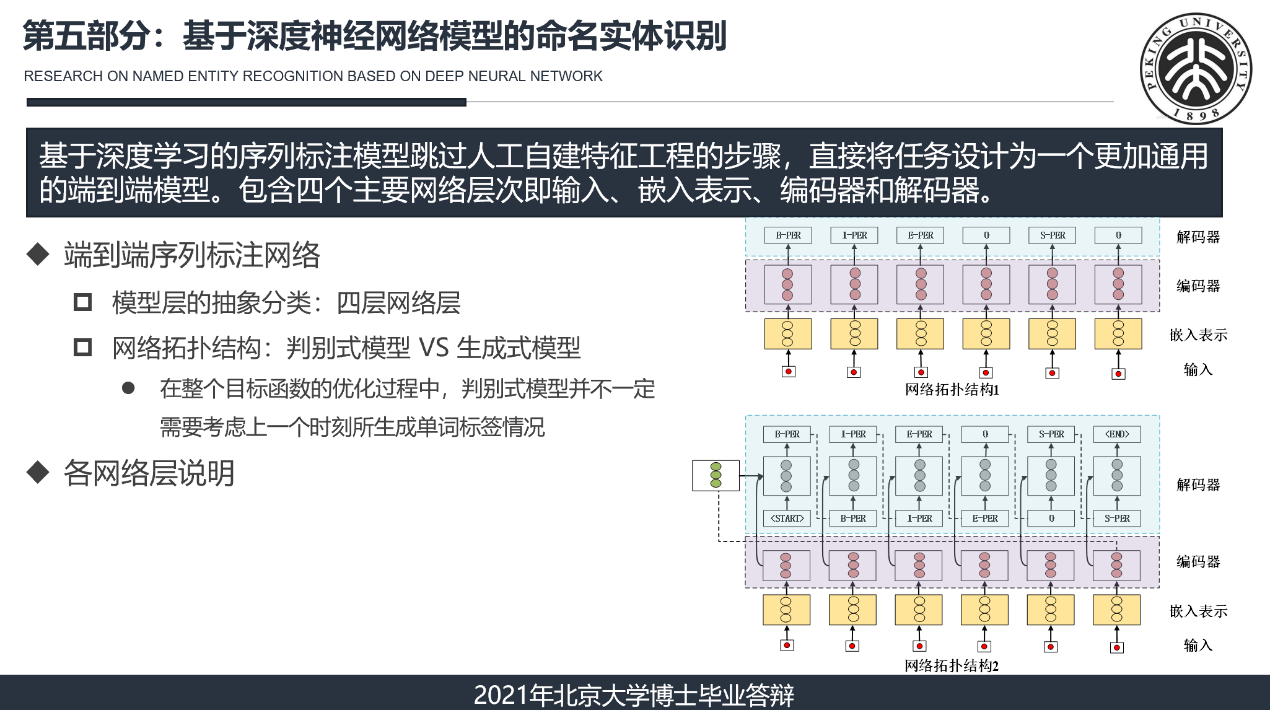
严承希答辩展示内容
在数据层中,通过结合规则匹配和专家校对等方法对原始古籍文本进行快速实体识别,并将其转化为标准数据集。在模型层中,相关数据会被引入到深度神经网络模型中进行解码预测,然后基于增强式主动学习技术来自动选择出“关键性”的样本集,并通过人工交互式标注和众包标注决策模型输出可靠的新训练样本。在应用层中,开发了一个古籍命名实体识别系统,该系统已经集成到“吾与点”古籍智能整理平台(https://wyd.kvlab.org),向用户提供公开服务。该研究提供了一个完整面向海量古籍资源的命名实体识别方案,在大大降低人工成本的同时确保了少资源条件下机器模型预测的准确性,并实现了实验室成果向工程产品化转化。
研究成果展示后,各位评审老师高度肯定了两位同学在数字人文领域进行跨学科探索的价值与创新性,高度认可了利用信息技术处理古籍资源的学术价值与应用前景,并给出了宝贵的意见。老师们对机器学习模型设计、模型结果、研究可扩展性等方面提出了相应问题与建议,如徐永明教授提问模型自动分类与人工分类结果存在差异的原因,童云海教授指出古籍命名实体识别模型的泛化性还有待进一步提升等。经答辩委员会无记名投票表决后,由答辩委员会主席童云海教授宣读了张力元与严承希全票通过博士学位论文答辩的决议。

两位同学与答辩委员会专家
【个人简介】
张力元,北京大学信息管理系2017级情报学专业博士生,研究方向为数字人文、知识组织、文本挖掘,获北京大学优秀科研奖、三好学生标兵等荣誉。毕业后将于北京大学任职。
严承希,北京大学信息管理系2016级情报学专业博士生,哈佛大学量化社会研究中心IQSS访问学者,研究方向为数字人文、机器学习、信息检索,获北京大学校长奖学金、专项奖学金、优秀科研奖等荣誉。毕业后将于中国人民大学任教。
【对母校/学院/导师想说的话】
光阴荏苒,在燕园已度过四年时光。我要感谢信息管理系和王军教授对我的培养。还记得每当我在科研中遇到困难时,王老师总能悉心指教,帮助我提高逻辑思维和独立科研能力。而当我在成长中遇到困惑时,王老师常借用朱子的话来启发我。更重要的是,王老师为我打开了一扇文史哲方向的窗,指引我走上数字人文这条道路,开拓了我的视野,也结识了许多志趣相投的老师与同学。忠心祝愿北京大学数字人文研究中心越办越好,为北大跨学科研究继续添砖加瓦!
——张力元
蓦然后首,我由衷感谢母校对我的培养,导师的教诲以及信息管理系和数字人文中心的老师和同学们的帮助。王老师是一位学术严谨和思想活跃的学者,尤其是他对情报学事业和人文科学发展的关切和热爱一直深深地感染和激励着我,特别是在我遇到问题和瓶颈的时候,他总能从旁进行指导和勉励,指引我迎接更多的挑战。未来我将继续秉承北大校训之精神,效仿贤师治学之态度,以梦为马,不负韶华。
——严承希
供稿:张力元、严承希
整理:薛晨桥